二者的确长得很像,但用途和功能却有本质区别。接出来,我们用简单的方法来理解。 简单理解:一个比喻就够 假如你用过百度,理解上去就更容易了。和的区别,就好比手机上的百度APP和百度浏览器: 换句话说,APP如同是“百度APP”,而如同是“...
Tag:GoogleChrome浏览器e04月28日
当前,人工智能领域迅猛发展,模型间的竞争愈发激烈。其中,「o1」模型展现出强大的复杂推理能力,在多个领域表现出色,其水平甚至超过了人类博士,这一成就令人称奇,同时也激发了人们对人工智能未来无限可能的憧憬。
「o1」模型的推理核心机制
「o1」模型有个特点,那就是在给出回复之前,它会多花些时间去思考。比如说,在解决AIME考试题目时,这种机制就显得尤为重要。它和那些迅速给出答案的传统模型不同,它更像人类,能在内部形成一条较长的思维链条。这就像学生在面对复杂题目时,每一步的推理都是紧密相连的,而不是草率地给出答案。这种机制使得它在科学、编程、数学基准测试等多个领域,都比其他模型表现得更加出色。
「o1」的这种机制是其LLM领域进步的核心所在。它非常看重思考时间,这让它能够进行多层次、多步骤的推理,这也是它取得优异成绩的技术支撑。在做出反应前,它会将各种信息整合起来,其处理方式与人类解决复杂问题的思维方式相似。
「o1」在各领域的出色表现
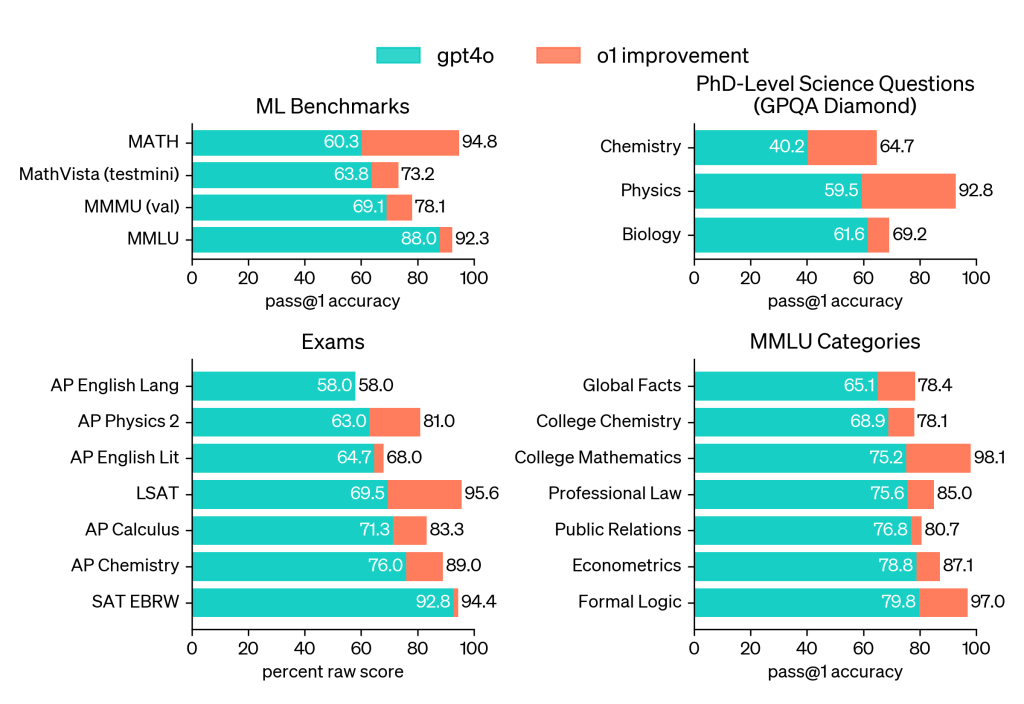
数学界中,以2024年的AIME考试为例,「o1」的表现极为突出。与「GPT - 4o」仅解决12%的问题相比,「o1」在单样本测试中取得了74%的佳绩。在多样本测试中,其成绩更是出类拔萃。在模拟编程竞赛中,其评估标准贴近真实竞赛,且能提交多达10份代码进行验证,整体表现同样值得称赞。
在物理、生物等众多学科中,「o1」的能力已达到或超过了博士级别。这说明它对跨学科知识的理解和运用十分出色。若将其比作学生,那它无疑是一位全能的学霸,面对理科知识、编程难题等,都能轻松应对。
训练方式助力推理能力提升
「o1」通过强化学习来执行复杂的推理任务。其训练方法别具一格,仿佛是让AI与自己的不同版本进行“对弈”或是“互动”。这个过程犹如高手之间的较量,通过不断切磋来提升自己的能力。
这种方式在游戏AI领域已取得显著成效。模型能生成众多推理步骤或思考路径,并经过评估和比较,挑选出最佳结果。在此过程中,模型不断学习,优化自身。这些训练步骤共同塑造了其目前强大的推理能力。
与传统生成式大模型的对比
传统的大规模生成模型通常迅速给出答案,属于快速思考方式。然而,「o1」虽然响应较慢,却通过逐步、反复的推理,在数学和科学领域显著增强了推理效能。若将传统模型比作追求速度的短跑选手,「o1」则更像稳扎稳打的马拉松选手,每一步都经过深思熟虑,最终获得优异成绩。
传统模型在处理简单需求时或许效率较高,但面对复杂数学和科学难题时,往往会出现不足。相比之下,「o1」模型通过多步骤的思考方式,显得更为周密和精确,这正是它与传统模型最大的不同之处。
「o1」模型的局限性

尽管「o1」功能强大,但同样存在不足。它的反应速度较慢,这在需要迅速获取答案的场合可能不太合适。若用户急需进行编程调试,可能无法忍受「o1」缓慢的处理过程。此外,目前「o1」尚不具备网页浏览和文件处理等能力,这些功能是GPT 4o所拥有的,而「o1」暂未实现。不过,官方已经表示未来将逐步引入这些功能。
关于「o1」的使用情况和未来展望
现在有一些用户能够运用「o1」模型。比如,Plus和Team的用户可以访问,还有那些达到5级API使用量的开发者可以进行原型设计。这表明「o1」模型正逐渐被更广泛的用户所采用。同时,官方也在积极增加用户的使用次数,这对于用户来说是个好消息。
你认为“o1”将来在人工智能界能否引发更强烈的变革浪潮?欢迎留言交流。同时,也请给这篇文章点赞和转发。
本文目录一览: 1、steamdeck能玩黑神话悟空吗 2、steamdeck能玩的游戏详细介绍 3、steamdeck能玩怪物猎人荒野吗 4、steamdeck能玩大表哥2吗 steamdeck能玩黑神话悟空吗 1、Stea...
Tag:steamdeck能玩什么游戏Steam平台下载e